
2022年08月05日

原文标题:《以太坊->Solana->Aptos:高性能区块链竞争开始了》
作者:推特@TheAntiApe
翻译:推特@0xshushu
主要结论:
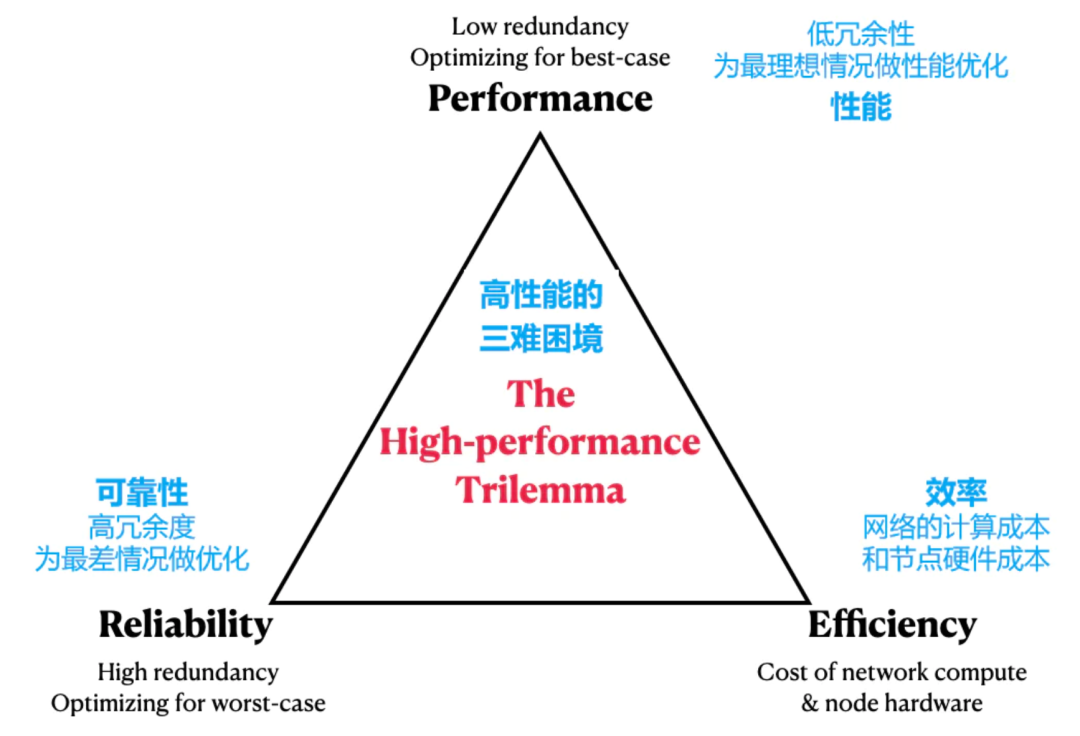
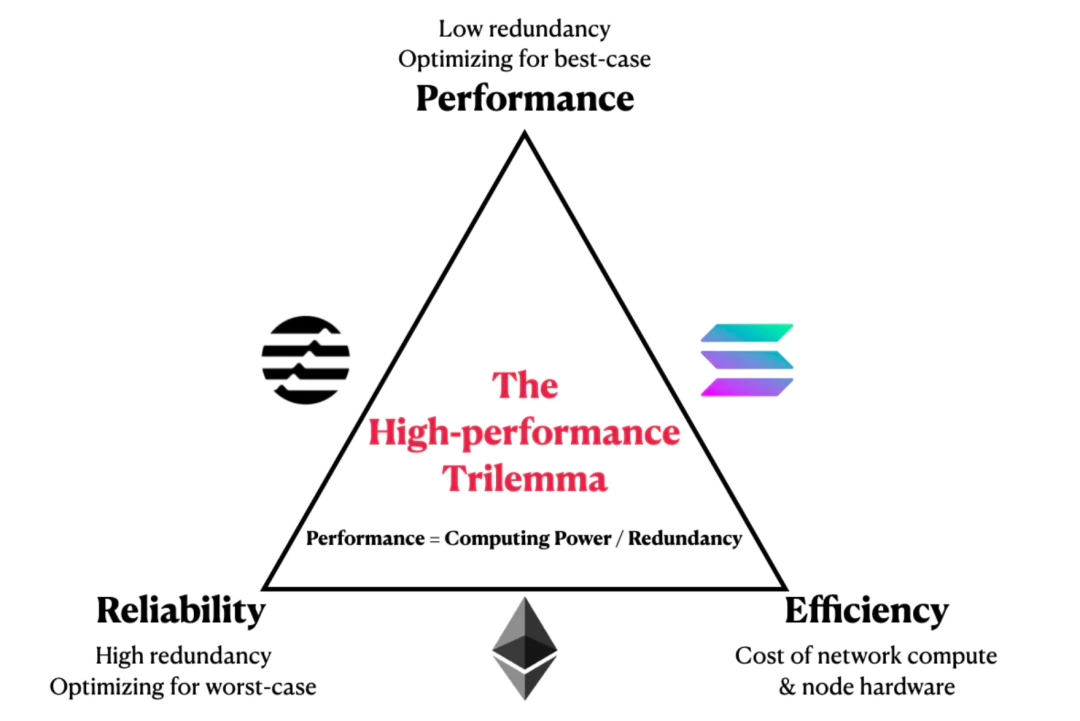
我们提出了一个L1设计权衡的第一性原理框架:高性能的三难困境。(如上图)
与以太坊相比,Solana的激进的低冗余设计既解释了它的高性能,也解释了它的低可靠性。
Aptos,一个拥有2亿美元全明星种子轮融资的新L1,准备挑战Solana在高性能L1领域的垄断地位。与Solana相比,Aptos增加了更多的可靠性,其代价是更高的节点硬件要求。
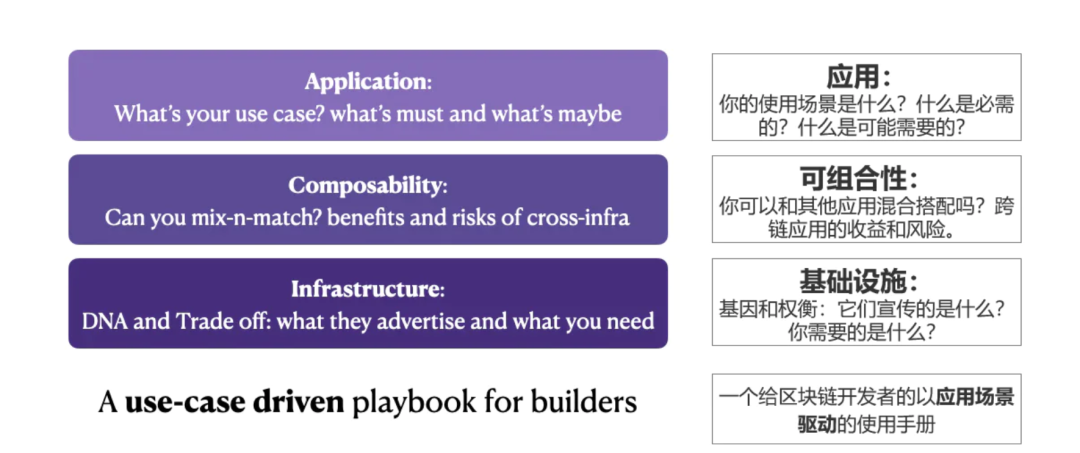
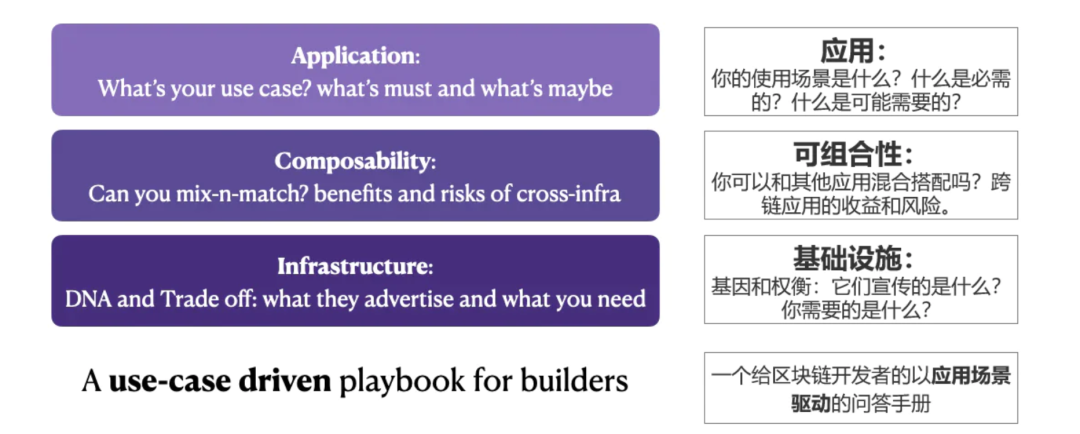
我们相信针对特定应用进行优化才是L1的未来。考虑到三难问题,没有哪条链能达到一个万能设计就符合所有应用场景的状态。在我们之前的跨链文章的基础上,我们提出了一个“三个问题”的问答手册,供区块链应用的开发者们考虑他们的技术选择。
这里篇幅有限,但我们其实有更多的想法。
我们诚挚地邀请感兴趣的建设者和投资者进行进一步的讨论。我们的推特是 @TheAntiApe,邮箱是 theantiape@gmail.com。
文章中会提及的项目包括:
Solana, Aptos, Ethereum, StarkWare, zkSync, Serum, Meteplex。
第一部分:Solana高性能的秘诀
这部分包括:
直到目前,Solana作为唯一的一条高性能区块链仍处于垄断地位
Solana的设计基因是激进地优化最理想情况下的网络性能:并行运算、减少冗余度和更高的出块率。
是什么让Solana与众不同?
作为唯一接近Visa 65,000 TPS容量的区块链,Solana获得了华尔街和硅谷的支持,以尝试应用大规模的区块链服务。
Solana并没有通过一些图灵奖的魔法来实现TPS(与零知识证明不同,这是我们即将讨论的另一个重要话题)。
相反,Solana在性能和可靠性之间做了一系列的设计权衡。我们将在第一部分讨论Solana的性能,在第二部分讨论可靠性的成本。
设计选择1:并行计算。
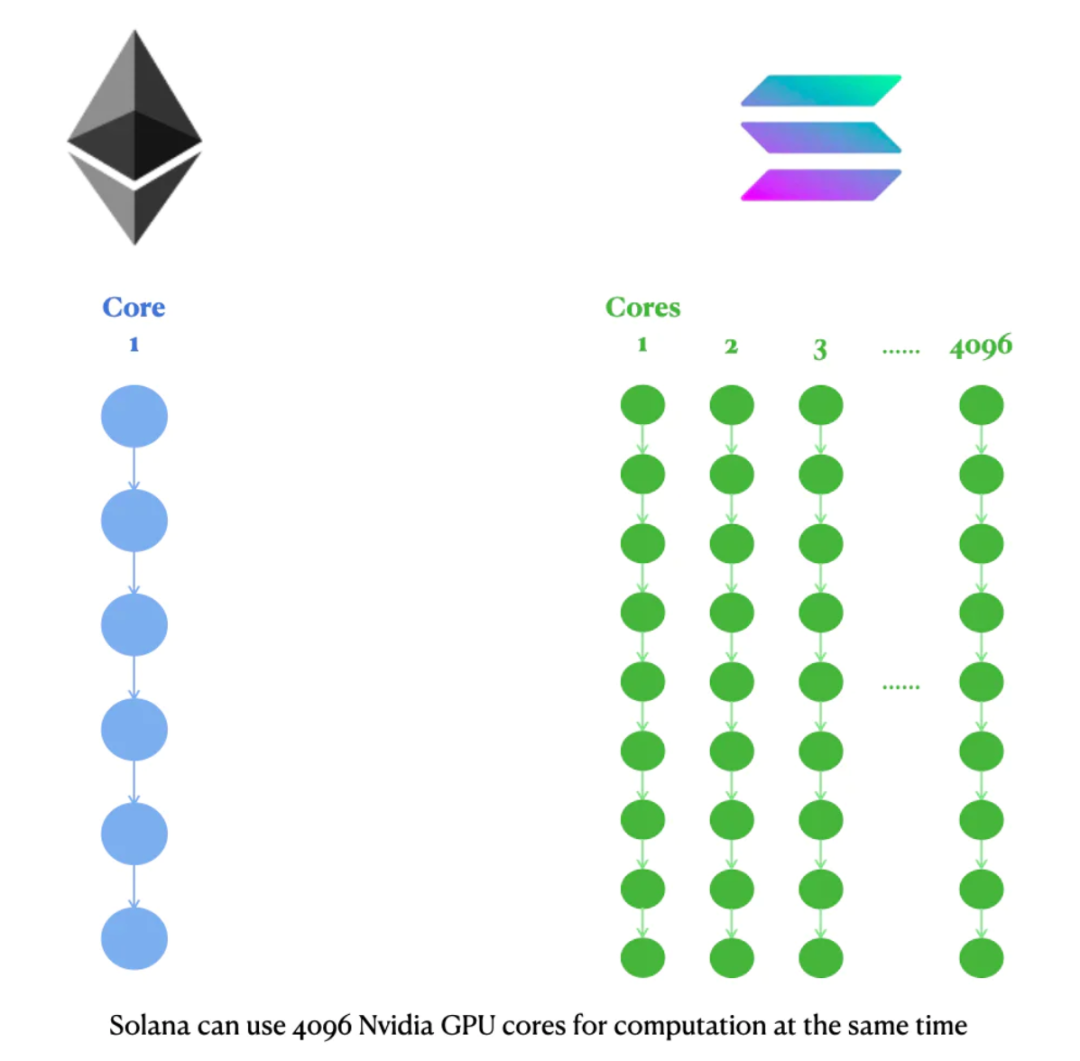
以太坊虚拟机(EVM)是单线程的——EVM只能利用一个CPU核心来按顺序处理交易。由于单核产生的热量随着速度的提高而呈指数级增长,物理学限制了单核性能的上限是很低的。
解决方案是什么?更多的核心! 八个2GHz的核心比一个8GHz的核心温度要低很多,但也更强大。
2007年,英特尔推出了双核的奔腾处理器,从而结束了单核时代。今天的计算机消费者拥有的GPU和CPU有4到4096个核心。
让更多的核心合作得更好,而不是拥有更强大的单核,已经成为了十多年来半导体行业的研究重心。

为了实现原生多线程,Solana必须放弃EVM的兼容性。Solana的智能合约可以利用Nvidia GPU的4096个核心来并行地运行计算。
我们的观点:在这个[EVM v.s Multi-thread]的二元选择中,我们倾向于多线程而不是EVM的兼容性。我们认为2027年的DApp却只能使用2007年的半导体技术是非常荒谬的。‘
’
有些人可能会指出 EVM/Solidity 相关的开发者的护城河问题。但是开发者其实很容易转换编程语言。
今天的大多数Web 2应用和开发人员使用的编程语言都是原生的多线程。我们认为未来的开发者会像当前高GAS一样对EVM的神秘的单线程架构感到沮丧。(另外,我们也不是EVM兼容的rollups方案的粉丝)。
设计选择2:通过确定的领导节点轮换减少冗余度
去中心化需要冗余性。在谷歌这样的中心化云服务中,计算只发生一次——因为用户相信谷歌是正确的。
在区块链中,由于我们不能信任任何人,所有数据都需要由不同的节点进行计算和验证。一个相同的计算所做的额外次数就是所谓的间接费用/冗余度。为了量化冗余,我们使用Big-O符号(大O符号,渐进符号),如[O(n^2), O(n), O(log n)],里面的函数表示当他们扩展到更多节点时,网络计算将变得多么复杂。例如,随着网络的增长,O(n^3)可能意味着比O(n^2)大几个数量级的冗余度。
在比特币、以太坊和其他许多简单的PoS链中,共识的冗余度至少是O(n^2),与节点数量的平方成正比:每个区块都必须传输、检查和比较其他每个区块的工作。
对于Solana,只有被指定的那个领导节点来生产下一个区块。(See Gulf Stream, Leader Rotation)。在此基础上,Solana将区块分割成很多小块,然后只有一小部分节点验证者来验证每个小块(See Turbine),而不是所有的节点都要发送和验证所有的区块。
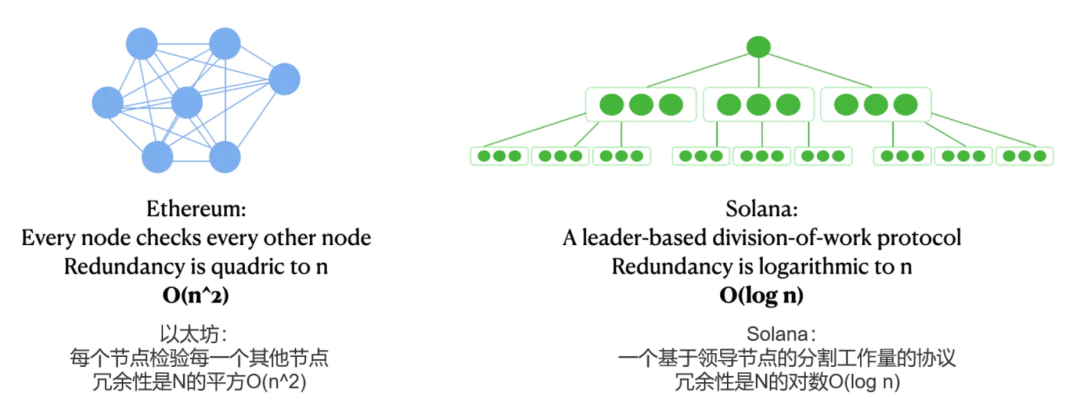
Solana的协议将Solana的最佳情况下的冗余度从O(n^2)减少到O(log n),这是计算复杂性理论中最有效的可能。
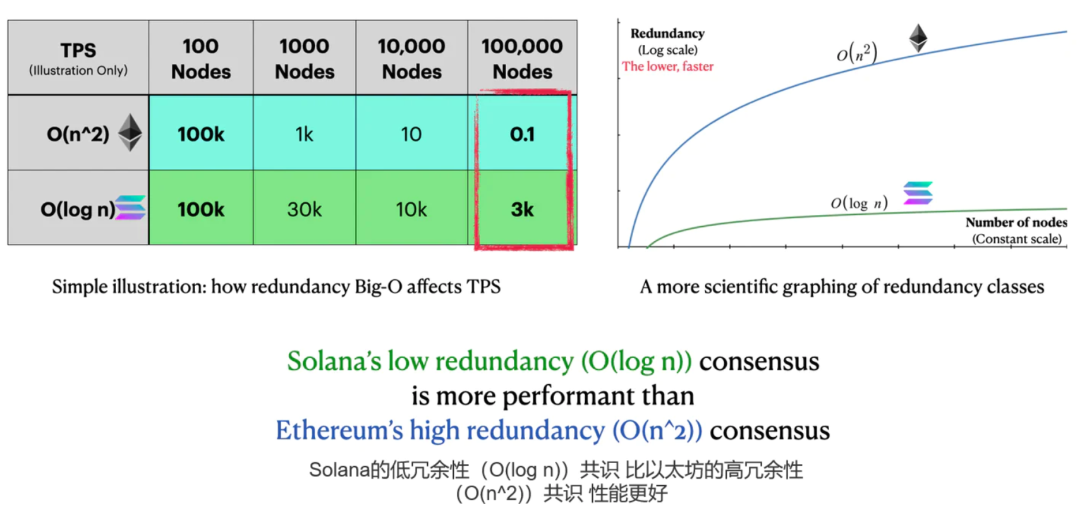
这个结果确实很了不起。考虑一个(过于简化的)说明。
网络A和B在其他方面是相同的,100个节点有100k TPS。
一个O(n^2)网络每增长10倍的节点性能就会衰减100倍。
一个O(log n)网络每增长10倍节点性能才会衰减~3倍。
在10万个节点时,两个网络的性能将相差30000倍。
这种复杂性的降低也有意识形态上的意义。
在这方面,我们认为Vitalik对Solana的批评有些误导——Vitalik认为Solana因为硬件要求高而不够去中心化。
Solana 4000美元的硬件成本阻止了 "每个用户在自己的机器上运行Solana节点"。这个成本是没错的。
但从长远来看,计算成本会越来越便宜,而且Solana的复杂度降低的设计使它有可能拥有100倍的节点,而不会使网络变得难以忍受的缓慢。
其他的设计选择:
支持者和批评者还就Solana的其他一些技术特点进行了辩论。我们认为这些特点不那么核心,所以我们概括性地讨论:
3.1 投票交易算入了TPS
一些批评者指出Solana通过将验证者投票也算入了交易,从而人为地增加了TPS。投票确实被算入了交易,但这只是一个表面问题。
也许Solana应该重申一下它的TPS是60,000(剔除投票交易),而不是65,000。
3.2 吞吐量—更快的出块时间和更大的区块
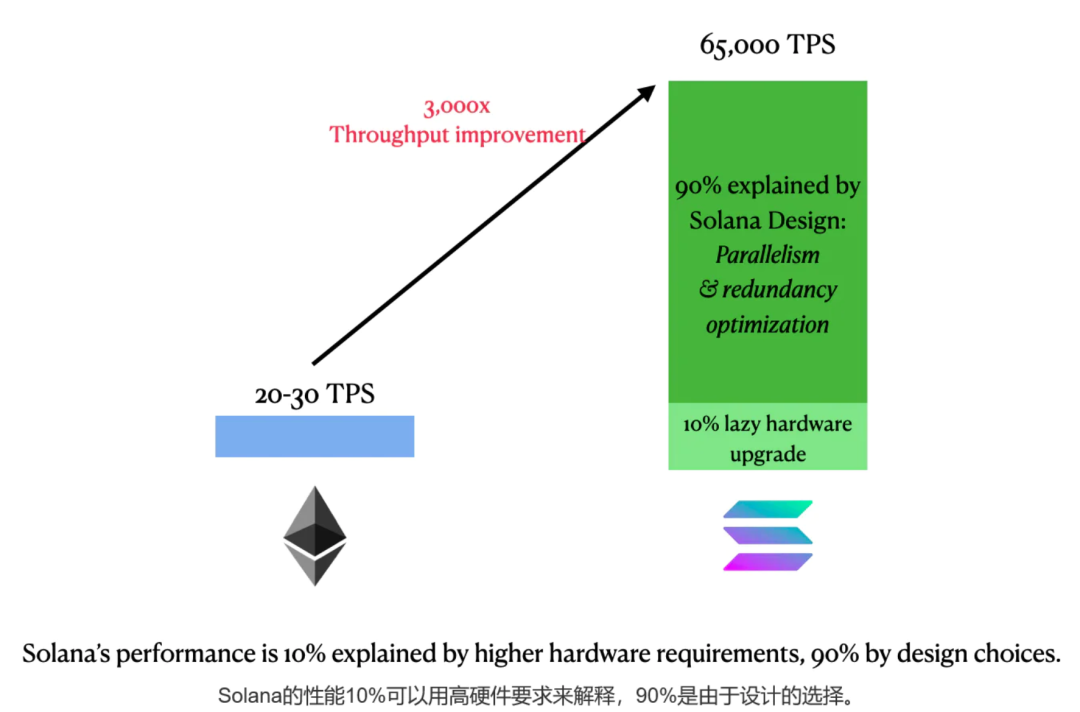
Vitalik和StarkWare都批评Solana的性能改进有些懒惰,因为Solana只是让每个区块更大,区块时间更短,以更高的硬件要求为代价来容纳更多的交易。
简单的数学会告诉你这并不是全部。
Vitalik和StarkWare都批评Solana的性能改进有些懒惰,因为Solana只是让每个区块更大,区块时间更短,以更高的硬件要求为代价来容纳更多的交易。简单的数学会告诉你这并不是全部。
Solana的最大区块大小为10MB,是ETH目标大小1MB的10倍。
Solana的出块时间是0.4秒,是以太坊12秒的30倍。
相比以太坊,以上两者的组合给了Solana大概300倍的懒惰性能改进。
但实际上Solana的TPS比以太坊通常的TPS要高3000倍。这另外90%的性能提升可以由我们讨论过的Solana的并行运算和降低冗余性的设计来更好的解释。
3.3 历史证明(POH)
Solana将POH宣传为其最大的创新。
从长远来看,历史证明允许Solana将区块时间减少到极端的400ms/区块,尽管事实上物理网络延迟往往大于400ms。这个功能的花哨名字是异步共识,更多细节见Multicoin的文章。
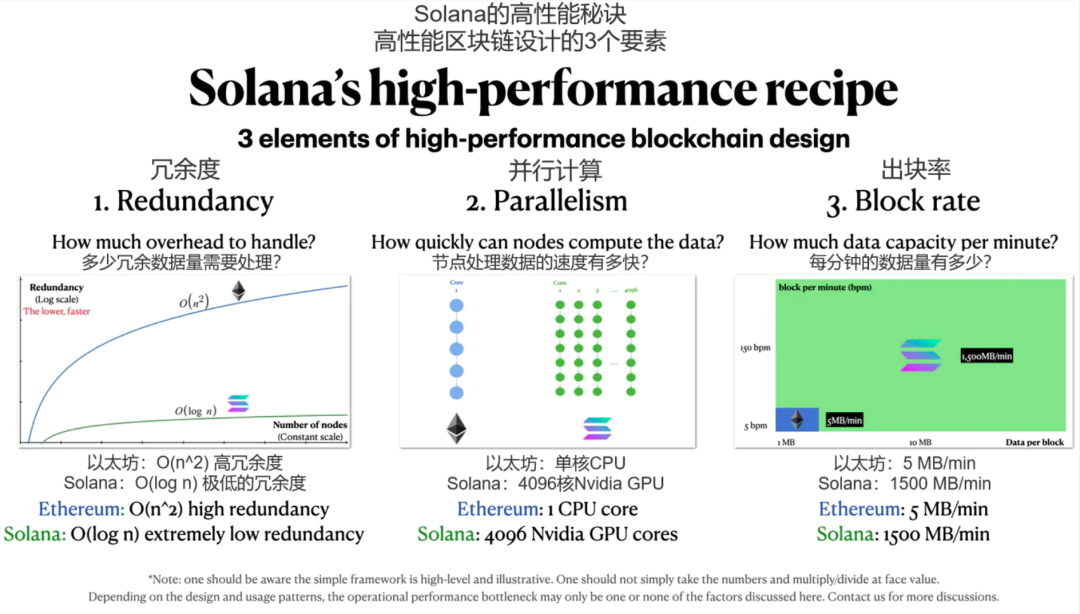
设计选择总结:Solana高性能秘诀
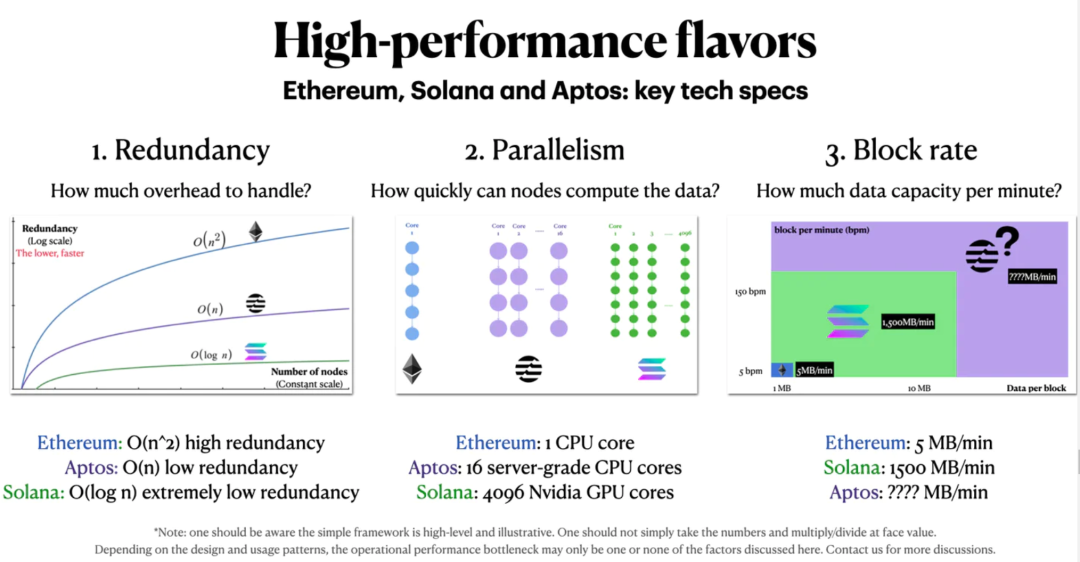
三个关键指标共同决定了区块链的最大吞吐量:出块率、并行计算和冗余性。
冗余度决定了总共需要多少数据和计算量,也就是说,总计算量=有效计算+冗余度;
并行计算允许节点计算的速度更快;
出块率决定了一定时期内区块链数据库中可保存的数据量。
Solana在这三个方面都做出了大胆的设计选择:从O(n^2)到O(log n)冗余;从1核到4096核并行,以及从5MB/min到1500MB/min的出块速率。
这些是Solana的65,000TPS背后的主要秘诀。在下一章中,我们将讨论Solana这些选择的成本。
第二部分:Solana选择的成本:优先性能而非弹性
这部分包括:
Solana激进的性能优化的DNA使它比其他区块链更容易发生故障。
我们提出了冗余困境:鉴于有限的计算能力,L1必须在性能和可靠性之间做出权衡。
冗余困境是第3部分中高性能三难问题的一个子集。
频繁的网络事故
在过去的一年里,Solana至少经历了4次重大网络事故。
2021年9月停运事故,2021年12月降级事故,2022年1月降级事故,2022年4月停运事故。任何有兴趣的利益相关者一定有很多问题:
是什么导致了事故?
本质的原因是是什么?一次性的系统BUG ?意外的攻击?还是区块链设计DNA中的某些问题,我们只能缓解?
选择最佳性能而不是可靠性
在第一部分中,我们讨论了Solana如何积极地优化其最佳情况下的性能。
"最佳情况 "是这里的一个关键词。当事情没有完全按照理想模式发生时,Solana就会失控。
设计成本1:当交易在逻辑上有顺序时,激进的的并行计算就会退化。
NFT mint 和IEO 交易常常导致Solana网络中断。
原因是:这些交易无法在4096个核心上同时进行。Minting NFTs 时,不知道哪些已经被mint 了,这会导致重复和BUG。
所有在同一个collection的mint交易必须按顺序处理。
一个直接含义就是,Solana的65,000 TPS并不意味着用户可以在一秒钟内铸造6个BAYC集合:由于只依赖一个GPU核心,Solana的按顺序处理能力可能更接近甚至低于以太坊,大约在10到100 TPS之间。
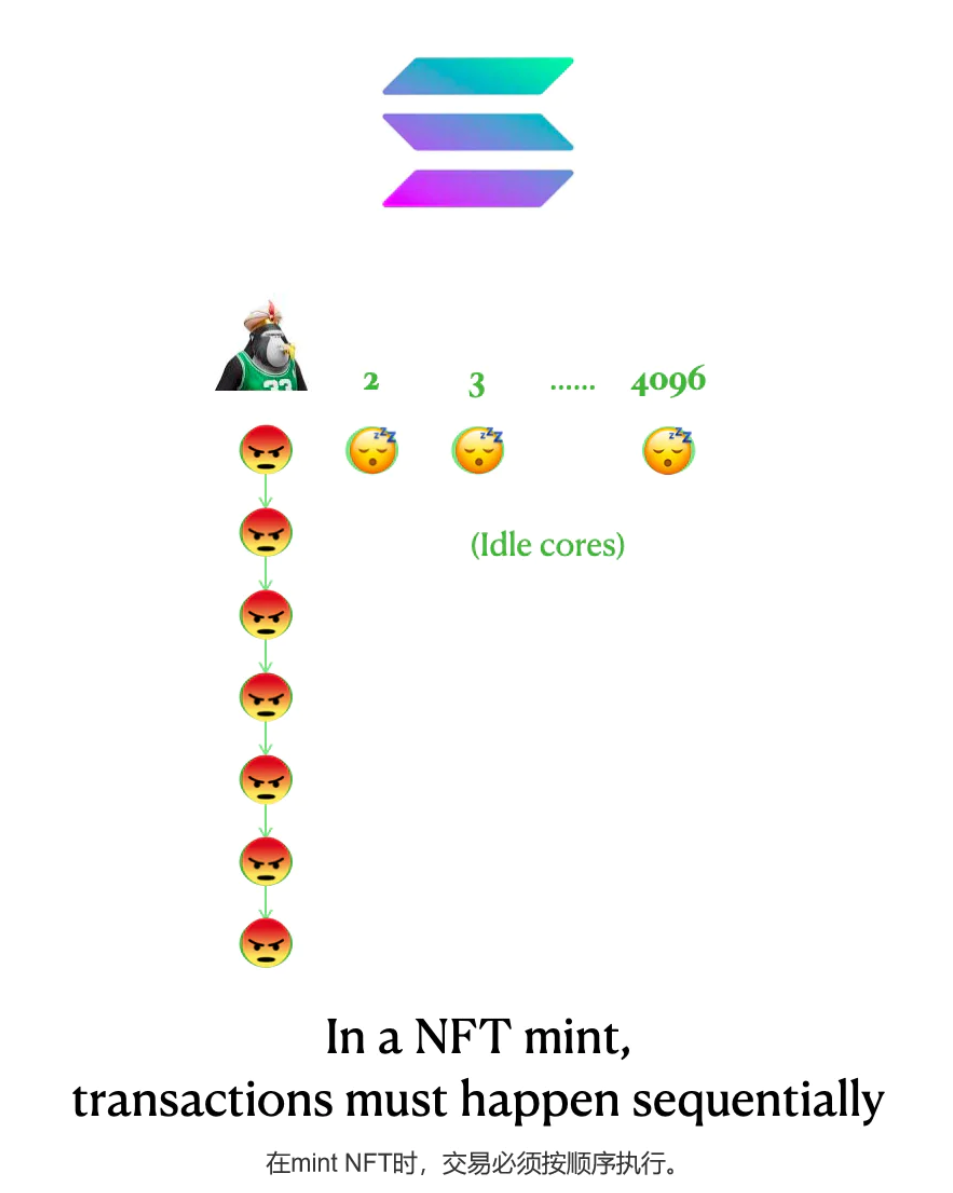
这就解释了性能下降的原因:NFT mint 时失控的交易量会使Metaplex无法使用,但其他不依赖Metaplex的应用(如Serum订单簿)仍然可以在其他4095个核心之一上处理交易。
但更多的时候,性能降低变成了网络中断:等待Metaplex的未处理的交易致使节点内存溢出——当内存溢出时,节点崩溃并完全离线。
核心权衡:通过使用4096核心的GPU而不是16核CPU,Solana牺牲了单核性能而支持激进的并行运算。通常情况下,当交易不相关时,网络运行得很好,但一旦交易表现出不理想的模式,Solana比高冗余度的以太坊更容易崩溃。
设计成本2:当领导者崩溃时,决定性的领导者选择会变得很难看
当Solana接近崩溃时,负责当前的区块领导节点往往是第一个崩溃的。
Solana的低冗余设计严重依赖领导结点是否在线--其他节点都没有与当前领导节点相同的交易数据或网络角色。
这意味着一旦领导节点离线,网络的其他部分需要做大量的应急工作:同意跳过一个区块,重新组织交易数据,并将丢失的交易数据转发给下一个领导节点......
考虑以太坊网络,它没有领导节点,每个节点都有一份精确和重复的副本,这份副本中包含有将被放入一个区块(mempool)的交易数据。
如果任何以太坊节点离线,所有其他节点手头仍有他们需要产生一个新区块的所有内容。
这就是冗余的双刃剑:在理想的情况下,冗余导致了网络的缓慢;但在坏的情况下,它可以防止重大事故。
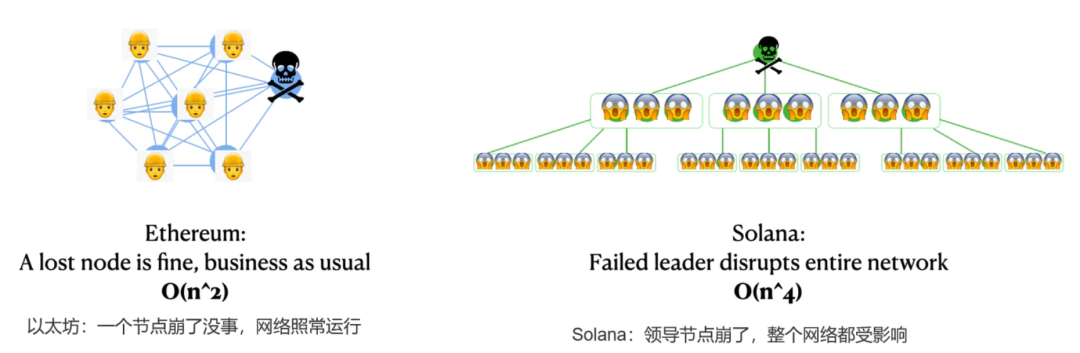
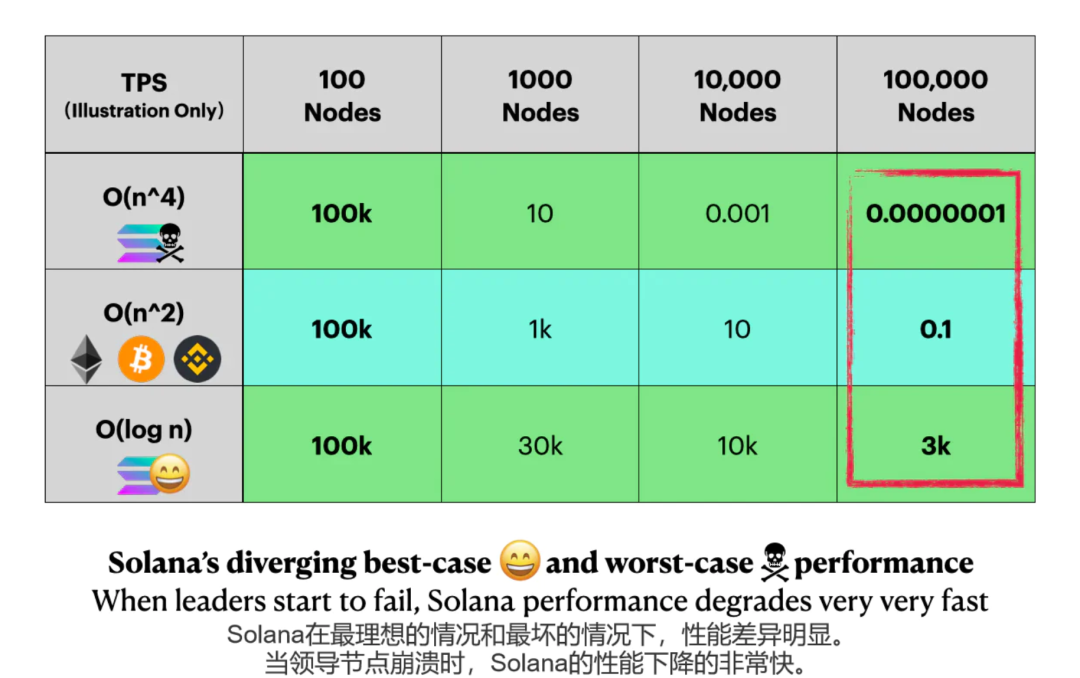
让我们用数字来说明。根据这篇论文,在领导者节点崩溃的情况下(正式称为 "级联领导者故障 cascading leader failure"),Solana的紧急计算量开销可以达到O(n^4)。
一个O(n^2)的网络很慢,但可以使用,然而一个一下子需要O(n^4)计算量的网络就好比死了。
这就是为什么Solana一旦进入O(n^4)级联领导故障模式,就难以自行恢复的主要原因。
这是一种特性,不是BUG

Solana的基因是激进的以最佳性能为优先。这个原则在架构中无处不在,所以很难只改变一个地方而不改变其他一切。
(我们没有讨论这个问题,但为了说明相互依赖性,如果在CPU而不是GPU上运行,核心的PoH算法将是不切实际的。
而Solana的PoH—最理想情况下进行性能优化的数据管理系统使其难以实现类似ETH的mempool)。
再次说明,这是一个权衡,不能两全其美——要从根本上使Solana更加稳定,需要创造更多的冗余度,从而牺牲最理想情况下的性能。
即使是Solana的支持者,也需要做好心理准备,网络中断和性能降低还会发生很多次。
因为今天的Solana网络还远远没有尝试过所有可能的缓解措施。缓解措施是一个需要迭代的捉迷藏游戏。
有一天,Solana实验室的努力工作可能使99.99%的网络正常运行时间成为可能。
是,它从来都不意味着要达到100%的网络正常运行,今天的主网beta版离99.99%也还很远。
第三部分:Aptos加入了竞争和高性能的三难问题
这部分包括:
Aptos的设计选择是在可靠性和性能之间的折衷,位于Solana和Ethereum之间
我们提出了高性能、可靠性和效率之间的高性能三难问题
对开发者来说,未来的趋势是根据具体使用场景进行优化。我们提出了一个3个问题的问答手册来帮助开发者选择基础设施
在过往整整一年多的时间里,Solana仍然是高性能L1细分市场里唯一的名字。
现在我们有了Aptos,由Facebook的前Libra团队开发,并由a16z、Tiger、Multicoin和FTX投资。
Multicoin和FTX明显也是Solana的重注投资者。
Aptos最近成为头条新闻,因为他们声称有16万的TPS,显然将自己定位为Solana的竞争对手。
这也是我们为什么花这么多时间来剖析Solana的原因:这是一个最好的角度来结合实际理解Aptos:

回顾第二部分,以太坊对网络能够正常运行的时间进行了优化:
以太坊花费了大量的数据冗余来为最坏的情况做准备,所以几乎不可能用攻击来使以太坊网络中断。
而Solana是为最理想情况下的性能进行了优化,在冗余上花费较少,从而使网络在极端情况下的可靠性降低。
在解决冗余度困境时,Aptos试图从Solana退一步。下面是它的一些关键设计选择:
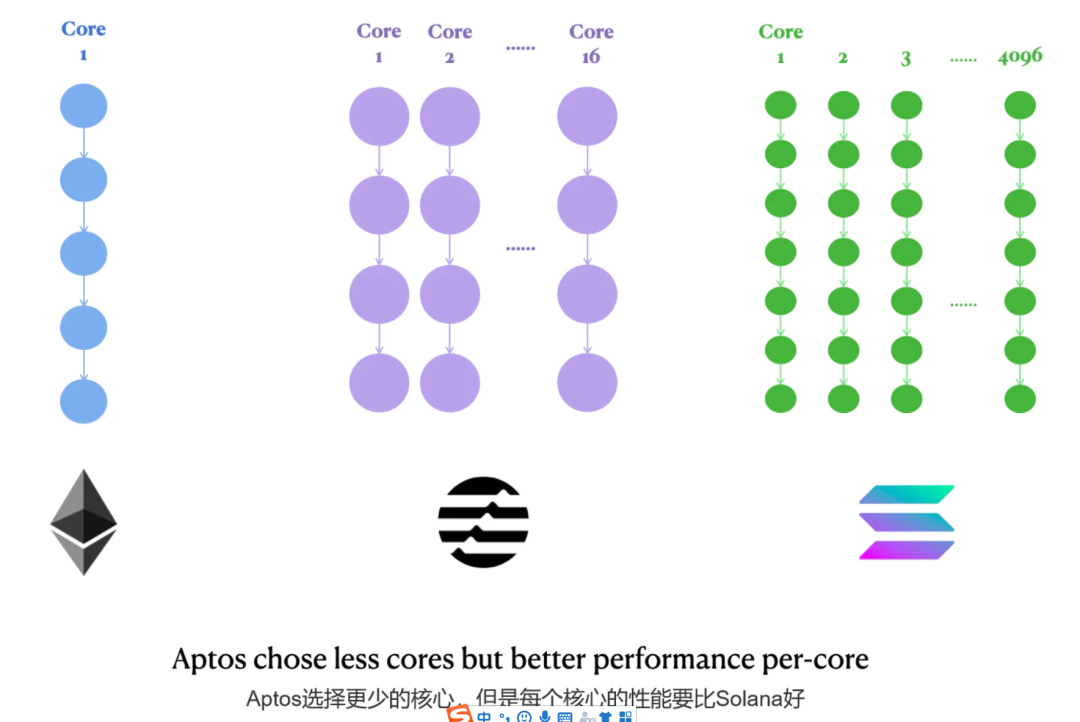
Aptos设计选择1:16核服务器级CPU
这是Solana的4096个GPU核心和以太坊的1个CPU核心之间的一个中间地带。
在处理高度可并行的任务时,Aptos可能不如Solana快。
Aptos的每个CPU核心都比Solana的GPU核心性能高得多,所以在NFT mint等逻辑上按顺序交易的情况下,Aptos可能比Solana处理得更好。
Aptos设计选择2:最理想情况冗余为O(n),最差情况冗余为O(n^2)
相对于Solana,Aptos试图通过增加冗余使其网络更具弹性。Aptos没有试图达到Solana的极端O(log n)次线性冗余度,而是设置为O(n)的冗余度。
在每一轮共识中,Aptos要求所有非领导者的节点同步额外的数据,以备当前领导者节点失败时其他节点需要接管。
Aptos也没有尝试对区块进行分割和验证,因为分割会在出错的情况产生额外的工作量。
这么设计的结果是:当领导者节点确实失败时,Aptos的应急处理并没有Solana那么混乱。
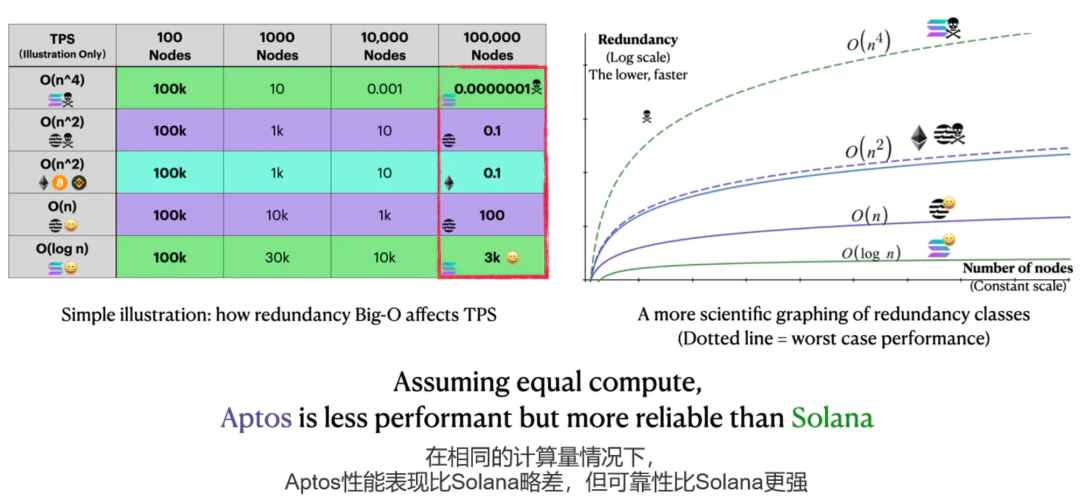
比较一下:Aptos的最佳性能不如Solana,但Aptos在最差情况下的表现更容易接受——O(n^2),而Solana为O(n^4)。
如果我们把这五个性能表现放在一起,它们刚好是一个漂亮的三明治,把Aptos(紫色)夹在Ethereum(蓝色)和Solana(绿色)之间。
Aptos设计选择3:疯狂的硬件要求
你们可能已经看到Aptos声称有16万的TPS,并想知道为什么我说其最理想情况下的性能不如Solana好。
注意Aptos的硬件要求:他们所有的测试都是在AWS EC2实例上运行的,有16核服务器级别的CPU。
Aptos还公开建议在谷歌云平台上运行他们的节点,而不是个人电脑。
16万这个数字是在大约100个有权限的节点上进行的实验室测试的结果——在更复杂的实际生产环境中,如果节点更多,TPS肯定会更低。
Aptos的内部测试也表明,随着网络扩展到更多节点,其性能将接近甚至低于Solana目前的65,000 TPS。
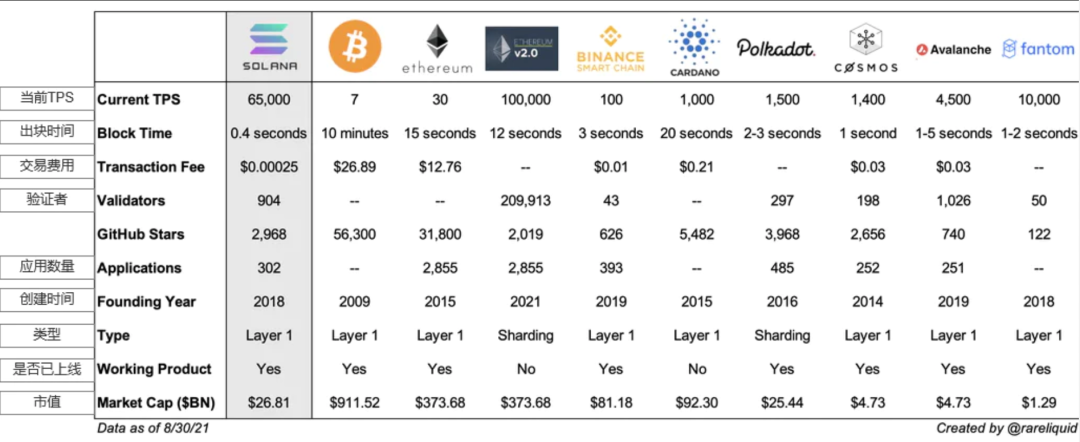
下面是对Aptos、Solana和以太坊关键技术规格的快速总结,供参考:
把所有东西放在一起总结一下:高性能的三难问题
把问题扩展到冗余困境,同时把Aptos变态的硬件要求也考虑在内,我们提出了一个Vitalik的区块链可扩展性三难问题的翻版:高性能三难问题。
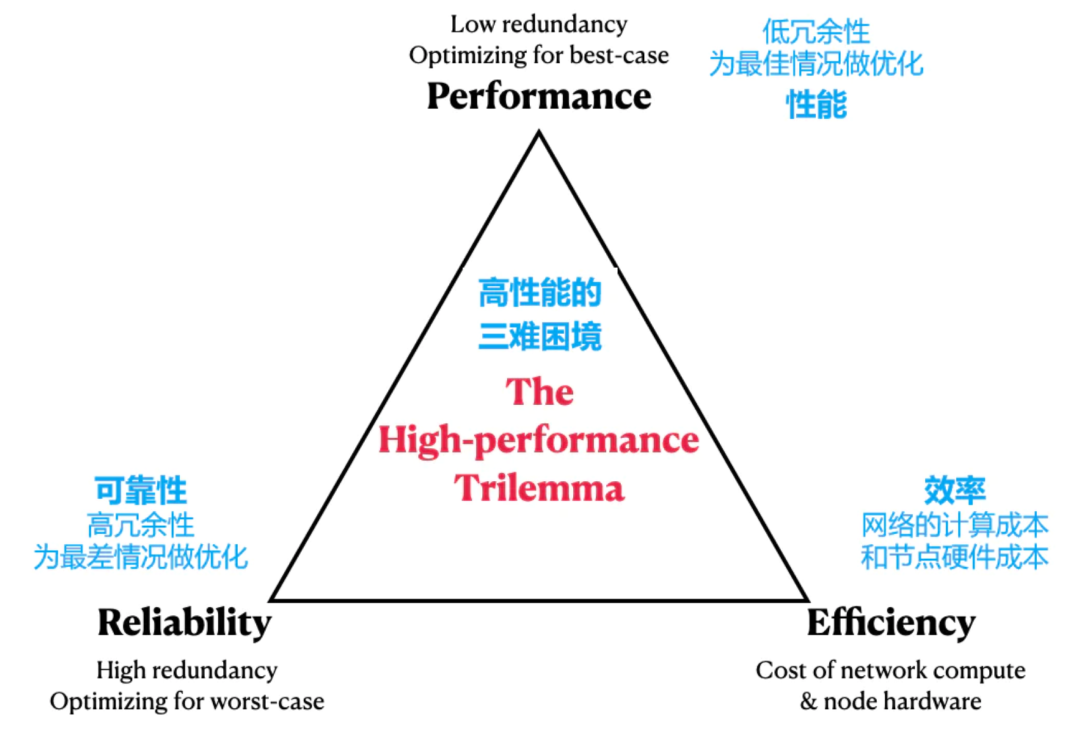
在这个三难问题中,三个不能同时满足的符合第一性原则的特质如下:
可靠性:通过在冗余度上花费更多的计算来保证网络正常运行时间
性能:通过在冗余上花费更少的计算来加强网络的吞吐量
效率:提升可靠性和性能的唯一方法是获取更多的计算资源来用于这两方面
在以太坊、Solana、Aptos三者中:
以太坊选择了网络正常运行时间和效率,所以它在冗余度上花费了的一定的计算量,导致性能缓慢。
Solana选择了性能和(相对)效率,所以它把有限的计算量都花在了最佳情况的性能上,较低的冗余度导致可靠性受到了负面影响。
Aptos选择了网络正常运行时间和高性能,所以为了有足够的计算来覆盖这两个方面,Aptos不得不选择基于服务器的节点,放弃了效率。
Aptos的设计理念相当Web 2:强调对用户的友好,而不是去中心化。早期的描述表明,Aptos可能会整合一个带有密码恢复功能的高级用户账户系统。
从任何角度看,Aptos肯定不是最去中心化的区块链。它并不以意识形态的纯粹性为目标。
来自a16z和Tiger的2亿种子轮投资者将一些真正的资金和资源放在这个有点逆向的愿景背后。
这一切对投资者和开发者意味着什么?使用场景优化。
No Maxis.(非最大主义者)
No Maxis.(非最大主义者)
No Maxis.(非最大主义者)
根据你的使用场景进行优化。
甚至AWS(亚马逊云服务)也为不同的使用场景提供了几十种数据库配置,因为没有一个万能的解决方案。区块链是数据库。
成为一个最大主义者可能有助于在快速增长的投机市场中通过承担短期风险而获利,但部落主义不利于真正的价值发现和建设。
一个好的投资者和建设者应该对各方面的权衡持现实的态度,并真正理解你的用例,而不是沉溺于推销、泡沫和公关话术中。
现在我们对未来会发展成什么样只有一个广泛的轮廓。Solana和Aptos都将经历更多的错误,中断,微调和补丁。
Solana会再次瘫痪,Aptos也会。但这并不改变它们作为解决有利可图的高性能L1问题的顶级竞争者的地位。
对于开发者:至少需要知道三件事:
你的使用场景,什么是至关重要的,什么只是锦上添花。
你想使用的基础设施的利弊权衡和基因是什么样的?
混合和匹配的成本和效益。跨链解决方案和风险,The Anti Ape之前的文章。伟大的DApp利用区块链,糟糕的DApp被他们使用的区块链所消耗。
对于投资者来说:Aptos将在2022年发布公共测试网和代币。这意味着Solana在高性能区块链领域的垄断很快就会结束。
我们预计Solana的代币价格将经历一些卖压,因为投资者在高性能区块链这个垂直领域有更多的选择了。但现在说赢家还为时过早。
无论如何,Aptos看起来是一个Solana的有力挑战者,因为它试图平衡Solana的长期可靠性和其他的一些权衡点。
但我们还需要观察,Aptos团队是否能很好地执行落地,以及他们是否能挑战Solana两年的生态系统的领先优势。
声明:本内容为作者独立观点,不代表 CoinVoice 立场,且不构成投资建议,请谨慎对待,如需报道或加入交流群,请联系微信:VOICE-V。
来源: 戈多Godot
评论1条