2024年02月24日

原文作者:Zeke
原文来源:YBB Capital
前言
2月16日,OpenAI公布了最新的文本控制视频生成扩散模型“Sora”,通过多段涵盖的广泛视觉数据类型的高质量生成视频,展现了生成式AI的又一个里程碑时刻。不同于Pika这类AI视频生成工具还处于用多张图像生成几秒视频的状态,Sora通过在视频和图像的压缩潜在空间中训练,将其分解为时空位置补丁,实现了可扩展的视频生成。除此之外该模型还体现出了模拟物理世界和数字世界的能力,最终呈现的60秒Demo,说是“物理世界的通用模拟器”也并不为过。
而在构建方式上,Sora延续了此前GPT模型“源数据-Transformer-Diffusion-涌现”的技术路径,这意味着其发展成熟同样需要算力作为引擎,且由于视频训练所需数据量远大于文本训练的数据量,对于算力的需求还将进一步拉大。但我们在早期的文章《潜力赛道前瞻:去中心化算力市场》中已经探讨过算力在AI时代的重要性,并且随着近期AI热度的不断攀升,市面上已经有大量算力项目开始涌现,而被动受益的其它Depin项目(存储、算力等)也已经迎来一波暴涨。那么除了Depin之外,Web3与AI的交织还能碰撞出怎样的火花?这条赛道里还蕴含着怎样的机会?本文的主要目的是对过往文章的一次更新与补全,并思考AI时代下的Web3存在哪些可能。
AI发展史的三大方向
人工智能(Artificial Intelligence)是一门旨在模拟、扩展和增强人类智能的新兴科学技术。人工智能自二十世纪五六十年代诞生以来,在经历了半个多世纪的发展后,现已成为推动社会生活和各行各业变革的重要技术。在这一过程中,符号主义、连接主义和行为主义三大研究方向的相互交织发展,成为了如今AI飞速发展的基石。
符号主义(Symbolism)
亦称逻辑主义或规则主义,认为通过处理符号来模拟人类智能是可行的。这种方法通过符号来表示和操作问题领域内的对象、概念及其相互关系,并利用逻辑推理来解决问题,尤其在专家系统和知识表示方面已取得显著成就。符号主义的核心观点是智能行为可以通过对符号的操作和逻辑推理来实现,其中符号代表对现实世界的高度抽象;
连接主义(Connectionism)
或称为神经网络方法,旨在通过模仿人脑的结构和功能来实现智能。该方法通过构建由众多简单处理单元(类似神经元)组成的网络,并通过调整这些单元间的连接强度(类似突触)来实现学习。连接主义特别强调从数据中学习和泛化的能力,特别适用于模式识别、分类及连续输入输出映射问题。深度学习,作为连接主义的发展,已在图像识别、语音识别和自然语言处理等领域取得突破;
行为主义(Behaviorism)
行为主义则与仿生机器人学和自主智能系统的研究紧密相关,强调智能体能够通过与环境的交互学习。与前两者不同,行为主义不专注于模拟内部表征或思维过程,而是通过感知和行动的循环实现适应性行为。行为主义认为,智能通过与环境的动态交互、学习而展现,这种方法应用于需要在复杂和不可预测环境中行动的移动机器人和自适应控制系统中时,显得尤为有效。
尽管这三个研究方向存在本质区别,但在实际的AI研究和应用中,它们也可以相互作用和融合,共同推动AI领域的发展。
AIGC原理概述
现阶段正在经历爆炸式发展的生成式AI(Artificial Intelligence Generated Content,简称AIGC),便是对于连接主义的一种演化和应用,AIGC能够模仿人类创造力生成新颖的内容。这些模型使用大型数据集和深度学习算法进行训练,从而学习数据中存在的底层结构、关系和模式。根据用户的输入提示,生成新颖独特的输出结果,包括图像、视频、代码、音乐、设计、翻译、问题回答和文本。而目前的AIGC基本由三个要素构成:深度学习(Deep Learning,简称DL)、大数据、大规模算力。
深度学习
深度学习是机器学习(ML)的一个子领域,深度学习算法是仿照人脑建模的神经网络。例如,人脑包含数百万个相互关联的神经元,它们协同工作以学习和处理信息。同样,深度学习神经网络(或人工神经网络)是由在计算机内部协同工作的多层人工神经元组成的。人工神经元是称为节点的软件模块,它使用数学计算来处理数据。人工神经网络是使用这些节点来解决复杂问题的深度学习算法。
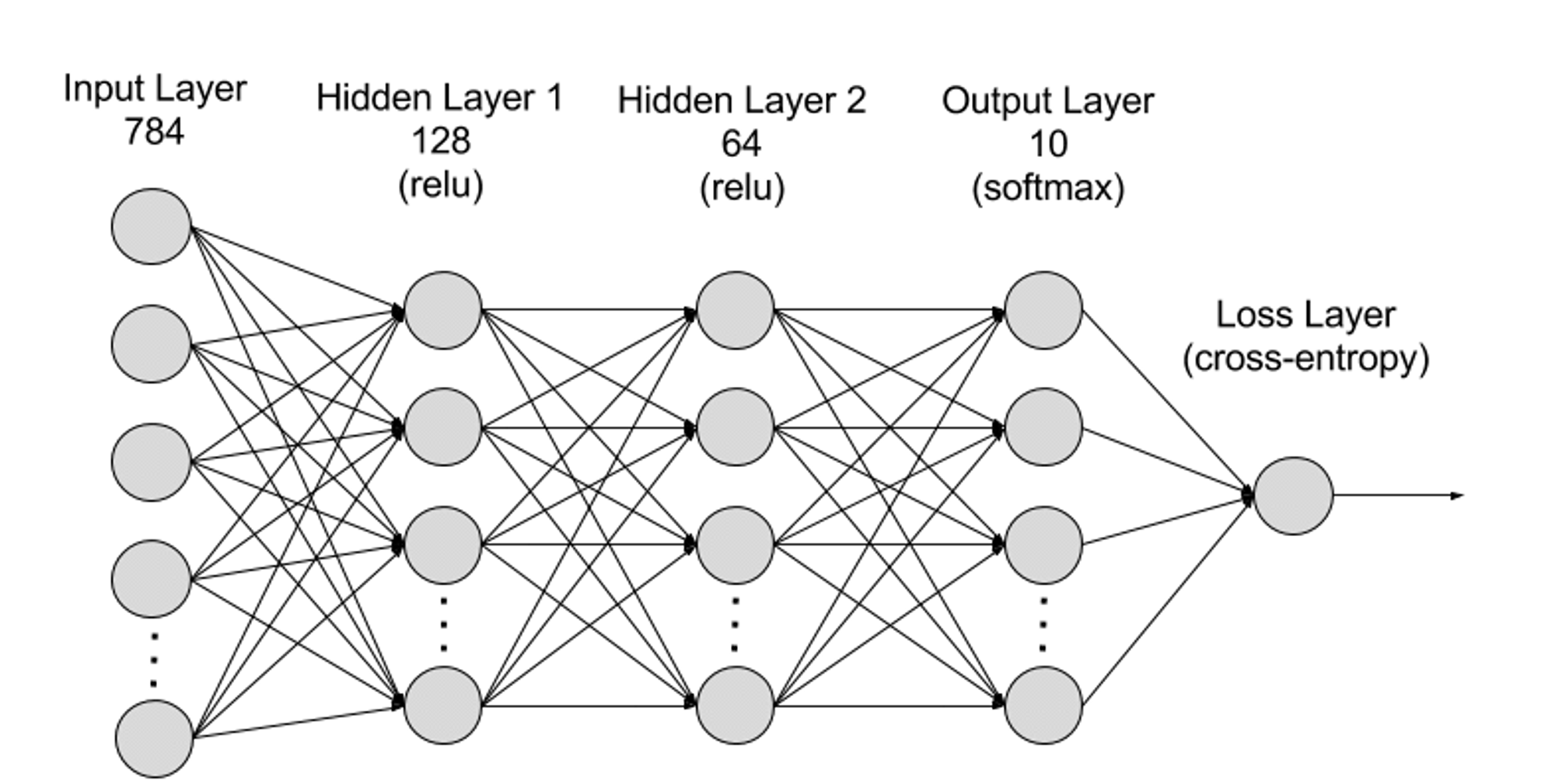
从层次上划分神经网络可分为输入层、隐藏层、输出层,而不同层之间连接的便是参数。
● 输入层(Input Layer):输入层是神经网络的第一层,负责接收外部输入的数据。输入层的每个神经元对应于输入数据的一个特征。例如,在处理图像数据时,每个神经元可能对应于图像的一个像素值;
● 隐藏层(Hidden Layer):输入层处理数据并将其传递到神经网络中更远的层。这些隐藏层在不同层级处理信息,在接收新信息时调整其行为。深度学习网络有数百个隐藏层,可用于从多个不同角度分析问题。例如,你得到了一张必须分类的未知动物的图像,则可以将其与你已经认识的动物进行比较。比如通过耳朵形状、腿的数量、瞳孔的大小来判断这是什么动物。深度神经网络中的隐藏层以相同的方式工作。如果深度学习算法试图对动物图像进行分类,则其每个隐藏层都会处理动物的不同特征并尝试对其进行准确的分类;
● 输出层(Output Layer):输出层是神经网络的最后一层,负责生成网络的输出。输出层的每个神经元代表一个可能的输出类别或值。例如,在分类问题中,每个输出层神经元可能对应于一个类别,而在回归问题中,输出层可能只有一个神经元,其值表示预测结果;
● 参数:在神经网络中,不同层之间的连接由权重(Weights)和偏置(Biases)参数表示,这些参数在训练过程中被优化以使网络能够准确地识别数据中的模式和进行预测。参数的增加可以提高神经网络的模型容量,即模型能够学习和表示数据中复杂模式的能力。但相对应的是参数的增加会提升对算力的需求。
大数据
为了有效训练,神经网络通常需要大量、多样及质量高和多源的数据。它是机器学习模型训练和验证的基础。通过分析大数据,机器学习模型可以学习数据中的模式和关系,从而进行预测或分类。
大规模算力
神经网络的多层复杂结构,大量参数,大数据处理需求,迭代训练方式(在训练阶段,模型需要反复迭代,训练过程中需要对每一层计算进行前向传播和反向传播,包括激活函数的计算、损失函数的计算、梯度的计算和权重的更新),高精度计算需求,并行计算能力,优化和正则化技术以及模型评估和验证过程共同导致了其对高算力的需求。

Sora
作为OpenAI最新发布的视频生成AI模型,Sora代表了人工智能处理和理解多样化视觉数据能力的巨大进步。通过采用视频压缩网络和空间时间补丁技术,Sora能够将来自世界各地、不同设备拍摄的海量视觉数据转换为统一的表现形式,从而实现了对复杂视觉内容的高效处理和理解。依托于文本条件化的Diffusion模型,Sora能够根据文本提示生成与之高度匹配的视频或图片,展现出极高的创造性和适应性。
不过,尽管Sora在视频生成和模拟真实世界互动方面取得了突破,但仍面临一些局限性,包括物理世界模拟的准确性、长视频生成的一致性、复杂文本指令的理解以及训练与生成效率。并且Sora本质上还是通过OpenAI垄断级的算力和先发优势,延续“大数据-Transformer-Diffusion-涌现”这条老技术路径达成了一种暴力美学,其它AI公司依然存在着通过技术弯道超车的可能。
虽然Sora与区块链的关系并不大,但个人认为之后的一两年里。因为Sora的影响,会迫使其它高质量AI生成工具出现并快速发展,并且将辐射到Web3内的GameFi、社交、创作平台、Depin等多条赛道,所以对于Sora有个大致了解是必要的,未来的AI将如何有效的与Web3结合,也许是我们需要思考的一个重点。
AI x Web3的四大路径
如上文所诉,我们可以知道,生成式AI所需的底层基座其实只有三点:算法、数据、算力,另一方面从泛用性和生成效果来看AI是颠覆生产方式的工具。 而区块链最大的作用有两点:重构生产关系以及去中心化。所以两者碰撞所能产生的路径我个人认为有如下四种:
去中心化算力
由于过去已经写过相关文章,所以本段的主要目的是更新一下算力赛道的近况。当谈到AI时,算力永远是难以绕开的一环。AI对于算力的需求之大,在Sora诞生之后已经是难以想象了。而近期,在瑞士达沃斯2024年度世界经济论坛期间,OpenAI首席执行官山姆·奥特曼更是直言算力和能源是现阶段最大的枷锁,两者在未来的重要性甚至会等同于货币。而在随后的2月10日,山姆·奥特曼在推上发表了一个极为惊人的计划,融资7万亿美元(相当于中国23年全国GDP的40%)改写目前全球的半导体产业格局,创立一家芯片帝国。在写算力相关的文章时,我的想象力还局限在国家封锁,巨头垄断,如今一家公司就想要控制全球半导体产业真的还是挺疯狂的。
所以去中心化算力的重要性自然不言而喻,区块链的特性确实能解决目前算力极度垄断的问题,以及购置专用GPU价格昂贵的问题。从AI所需的角度来看,算力的使用可以分为推理和训练两种方向,主打训练的项目,目前还是寥寥无几,从去中心化网络需要结合神经网络设计,再到对于硬件的超高需求,注定是门槛极高且落地极难的一种方向。而推理相对来说简单很多,一方面是在去中心化网络设计上并不复杂,二是硬件和带宽需求较低,算是目前比较主流的方向。
中心化算力市场的想象空间是巨大的,常常与“万亿级”这个关键词挂钩,同时也是AI时代下最容易被频繁炒作的话题。不过从近期大量涌现的项目来看,绝大部分还是属于赶鸭子上架,蹭热度。总是高举去中心化的正确旗帜,却闭口不谈去中心化网络的低效问题。并且在设计上存在高度同质化,大量的项目非常相似(一键L2加挖矿设计),最终可能会导致一地鸡毛,这样的情况想要从传统AI赛道分一杯羹着实困难。
算法、模型协作系统
机器学习算法,是指这些算法能够从数据中学习规律和模式,并据此做出预测或决策。算法是技术密集型的,因为它们的设计和优化需要深厚的专业知识和技术创新。算法是训练AI模型的核心,它定义了数据如何被转化为有用的见解或决策。较为常见的生成式AI算法比如生成对抗网络(GAN)、变分自编码器(VAE)、转换器(Transformer),每个算法都是为了一个特定领域(比如绘画、语言识别、翻译、视频生成)或者说目的而生,再通过算法训练出专用的AI模型。
那么如此之多的算法和模型,都是各有千秋,我们是否能将其整合为一种能文能武的模型?近期热度高涨的Bittensor便是这个方向的领头者,通过挖矿激励的方式让不同AI模型和算法相互协作与学习,从而创作出更高效全能的AI模型。而同样以这个方向为主的还有Commune AI(代码协作)等,不过算法和模型对于现在的AI公司来说,都是自家的看门法宝,并不会随意外借。
所以AI协作生态这种叙事很新奇有趣,协作生态系统利用了区块链的优势去整合AI算法孤岛的劣势,但是否能创造出对应的价值目前尚未可知。毕竟头部AI公司的闭源算法和模型,更新迭代与整合的能力非常强,比如OpenAI发展不到两年,已从早期文本生成模型迭代到多领域生成的模型,Bittensor等项目在模型和算法所针对的领域也许要另辟蹊径。
去中心化大数据
从简单的角度来说,将私有数据用来喂AI以及对数据进行标记都是与区块链非常契合的方向,只需要注意如何防止垃圾数据以及作恶,并且数据存储上也能使FIL、AR等Depin项目受益。而从复杂的角度来说,将区块链数据用于机器学习(ML),从而解决区块链数据的可访问性也是一种有趣的方向(Giza的摸索方向之一)。
在理论上,区块链数据可随时访问,反映了整个区块链的状态。但对于区块链生态系统之外的人来说,获取这些庞大数据量并不容易。完整存储一条区块链需要丰富的专业知识和大量的专门硬件资源。为了克服访问区块链数据的挑战,行业内出现了几种解决方案。例如,RPC提供商通过API访问节点,而索引服务则通过SQL和GraphQL使数据提取变得可能,这两种方式在解决问题上发挥了关键作用。然而,这些方法存在局限性。RPC服务并不适合需要大量数据查询的高密度使用场景,经常无法满足需求。同时,尽管索引服务提供了更有结构的数据检索方式,但Web3协议的复杂性使得构建高效查询变得极其困难,有时需要编写数百甚至数千行复杂的代码。这种复杂性对于一般的数据从业者和对Web3细节了解不深的人来说是一个巨大的障碍。这些限制的累积效应凸显了需要一种更易于获取和利用区块链数据的方法,可以促进该领域更广泛的应用和创新。
那么通过ZKML(零知识证明机器学习,降低机器学习对于链的负担)结合高质量的区块链数据,也许能创造出解决区块链可访问性的数据集,而AI能大幅降低区块链数据可访问性的门槛,那么随着时间的推移,开发者、研究人员和ML领域的爱好者将能够访问到更多高质量、相关的数据集,用于构建有效和创新的解决方案。
AI赋能Dapp
自23年,ChatGPT3爆火以来,AI赋能Dapp已经是一个非常常见的方向。泛用性极广的生成式AI,可以通过API接入,从而简化且智能化分析数据平台、交易机器人、区块链百科等应用。另一方面,也可以扮演聊天机器人(比如Myshell)或者AI伴侣(Sleepless AI),甚至通过生成式AI创造链游中的NPC。但由于技术壁垒很低,大部分都是接入一个API之后进行微调,与项目本身的结合也不够完美,所以很少被人提起。
但在Sora到来之后,我个人认为AI赋能GameFi(包括元宇宙)与创作平台的方向将是接下来关注的重点。因为Web3领域自下而上的特性,肯定很难诞生出一些与传统游戏或是创意公司抗衡的产品,而Sora的出现很可能会打破这一窘境(也许只用两到三年)。以Sora的Demo来看,其已具备和微短剧公司竞争的潜力,Web3活跃的社区文化也能诞生出大量有趣的Idea,而当限制条件只有想象力的时候,自下而上的行业与自上而下的传统行业之间的壁垒将被打破。
结语
随着生成式AI工具的不断进步,我们未来还将经历更多划时代的“iPhone时刻”。尽管许多人对AI与Web3的结合嗤之以鼻,但实际上我认为目前的方向大多没有问题,需要解决的痛点其实只有三点,必要性、效率、契合度。两者的融合虽处于探索阶段,却并不妨碍这条赛道成为下个牛市的主流。
对新事物永远保持足够的好奇心和接纳度是我们需要必备的心态,历史上,汽车取代马车的转变瞬息之间便已成定局,亦如同铭文和过去的NFT一样,持有太多偏见只会和机遇失之交臂。
声明:本内容为作者独立观点,不代表 CoinVoice 立场,且不构成投资建议,请谨慎对待,如需报道或加入交流群,请联系微信:VOICE-V。
来源:YBB Capital

简介:专注区块链发声










评论0条