2019年04月03日

虽然 ASIC 芯片设计不是太高深的事情,但想要深入理解也并非那么容易。

概述
只要与 ProgPow 和 Ethash 算法有关,市场上就会出现各种对矿机硬件设计和开发成本的推测,通常后面还会跟上一个权威声明:请相信发表预测的作者,因为他/她在相关行业领域里拥有丰富经验。这些推测有时会与加密货币 ASIC 芯片生产有关,还有些时候则是关于集成电路设计。对于那些更熟悉代码、却不太了解扇出(fan-out)和上升时间(rise-times)的读者来说,本文可能会对他们深入了解 ProgPow 算法有所帮助。
(星球君 o-daily 注:Ethash 是目前以太坊基于工作量证明的挖矿共识算法,ProgPow 是一个试图削弱 ASIC 矿机优势的挖矿算法。扇出是一个定义单个逻辑门能够驱动的数字信号输入最大量的专业术语。大多数的 TTL 逻辑门能够为 10 个其他数字门或驱动器提供信号,因此一个典型的 TTL 逻辑门有 10 个扇出信号;上升时间是脉冲技术里的一个专业名词,电压上升两个时刻的时间间隔就是网络变压器的上升时间。)
程序员总是会给人一种无所不能的感觉,从编写脚本到开发 iPhone APP,从嵌入式系统到 Windows 操作系统。但是,会写代码开发应用程序不代表你能成为 APP Store 应用商店后端(或改善系统效率)的权威人士,能够开发实时多任务操作系统(RTOS)也不代表你能成为扩展 Windows 操作系统成本权衡领域里的达人。
当然,作为 ProgPow 算法核心开发团队,IfDefElse 在此并不是说 Windows 设计师不是“优秀的程序员”,但必须要说明的是,由于不同人的技术背景不同,很容易造成对不同领域的理解和假设偏差,特别是在讨论规模经济话题的时候。
同样地,一名硬件设计师可能也会涉猎不同的领域,比如为一款电动牙刷设计芯片,或是为网络设备构建一个芯片架构(silicon architect)。生产 10 万个电动家牙刷芯片的工程师可能不会理解生产 100 万个芯片的网络工程师所考虑的可用规模经济,同样一个加密货币 ASIC 芯片设计师可能对 GPU-ASIC 芯片设计知之甚少——这些行业彼此之间的联系并不是很多,有的甚至是国与国之间的差距。
在概述中我们还要提的最后一点,就是编程和工程其实都是一种技巧,除非你每天都在编程写代码,否则很快就会落后、无法成为权威,因为这方面的知识更新迭代很快。或许这也是为什么新的加密货币 ASIC 制造商很难进入基于 SHA-256 算法的挖矿市场,毕竟一个新手程序员想要赶超已经研究 SHA-256 算法六年的工程师是不太可能的。
另一方面,加密货币生态系统里其实并没有太多文章介绍硬件知识。当然,加密货币本身就是一个以软件为主导的行业,而且绝大多数硬件工程都是在一些私人公司内部“闭门”研究的。
有些“硬件砖家”正在竭尽全力向软件工程师保证他们能够战胜加密货币生态系统——我们已经在门罗币(Monero)、比特币(Bitcoin)、以及 ZCash 等加密货币上看到了这种情况已经出现。但现实是,这种挑战至今仍没有发生,想想看,如果比特大陆或 Innosilicon 试图制造 CPU,你认为他们能够战胜英特尔和 AMD 吗?
解析 ASIC 芯片设计成本
规模经济总是普遍存在的——不管是从成本角度,还是经验角度。对于 ASIC 芯片设计成本, 芯片设计师们似乎总是存在很大争论,下面就让星球君(微信:o-daily)带大家一起看看解析一下受到业内关注的九个问题:
问题一:不管挖矿算法是 ProgPow,还是 ETHash,哈希值都是由外部动态随机存取存储器(DRAM)的存储带宽决定的,是这样吗?
事实并非如此。ProgPow 的哈希值是由两个因素决定的:
1、计算核心
2、内存带宽
这就是为什么 Ethash 和 ProgPow 之间存在差异,如下图 1 和图 2 所示:
图 1 :英伟达芯片产品挖矿哈希率比较
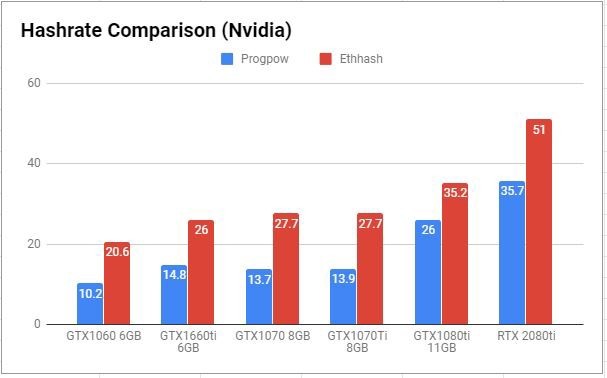
图 2 :AMD 芯片产品挖矿哈希率比较
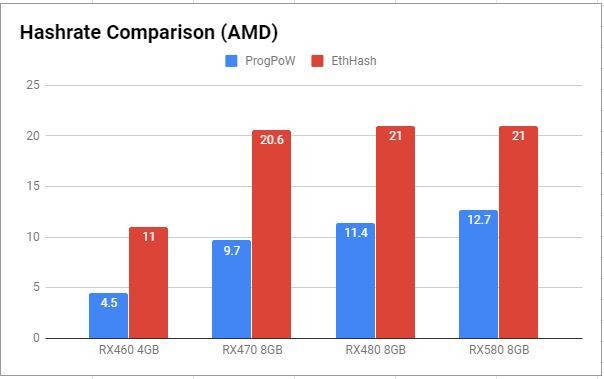
现阶段,ETHash 挖矿更有利可图,针对该算法的内存需求明显增加,对于高带宽存储器的需求不断增长也促使下一代高速存储器技术被开发了出来,比如 GDDR6(带宽速度达到 768 GB/s) 和 HMB2(带宽速度达到 256 GB/s)。
对于高带宽内存的需求并非全部来自“Ethash”,整个高带宽内存市场规模高达 150 亿美元,其中只有很少一部分来自采矿行业。高带宽内存的核心市场需求主要包括:GPU、现场可编程门阵列(FPGA)、人工智能(AI)、高性能计算(HPC)、以及游戏。相比于 1.2 万亿美元的人工智能市场、300 亿美元的 PC 游戏市场、350 亿美元的手持游戏机市场、以及 290 亿美元的高性能计算市场,挖矿行业的高带宽内存需求真的是“微不足道”。
问题二:由于 ProgPow 现有架构和算法与 ETHash 存在相似之处,Innosilicon 的下一款 ASIC 芯片将会为 ProgPow 量身定制吗?
事实上,ProgPow 和 ETHash 之间唯一的相似之处就是在全局内存(global memory)中使用了无环图(DAG)。从计算的角度来看,ETHash 只需要一个固定的“keccak_f1600”内核和一个模数函数(modulo function)。另一方面,ProgPow 需要的则是能够执行 16 通道宽的随机数学序列,同时还要能够访问高带宽一级缓存(L1 cache)。设计一个能够执行 ProgPow 数学序列的计算内核,比设计一个能够实现类似“keccak”这样的固定函数哈希要难得多。
另外需要注意的是,ETHash 的哈希值只取决于内存带宽,而 ProgPow 算法则同时取决于内存带宽和随机数学序列的核心计算——理解这一点非常重要。
工作量证明(PoW)的本质其实是通过耗费硬件和能源成本进行数学计算证明,作为一种算法,ETHash 在数学证明中并不会耗费大部分硬件费用(计算引擎)。相反,ETHash 只捕获内存接口,这就是为什么你可以使用一个用于加密货币挖矿的 ASIC 芯片来把数学计算中没有被捕获到的部分给消减掉。
问题三:由于 GPU 是通用加速芯片,因此设计、制造和测试 GPU 的周期通常需要大约十二个月,而且还需要进行大量硬件模拟和软件开发工作,使其能够覆盖不同的计算方案和场景。
ProgPoW 希望能够捕获全部硬件成本(尽可能地做到),由于该算法更新的部分能够捕获运行不同计算场景的计算硬件——直到架构褶皱(architectural wrinkles)——因此对于 ASIC 芯片设计来说,可能需要耗费不止 3-4 个月的时间。
由于时间跨度较长,随之会引发出另一个问题:为什么浮点运算(floating point operation)被省略掉了?这个问题的答案其实也非常简单:浮点运算不能跨芯片移植,不同芯片往往会以不同方式来处理与特殊值(比如下确界、非数字数值、以及相关变体等)相关的边界案例(corner case)。边角案例也被成为病态案例(pathological case),是指其操作参数在正常范围以外的问题或是情形,而且多半是几个环境变数或是条件都在极端值的情形,即使这些极端值都还在参数规格范围内(或是边界)。其中最大的分歧在于非数字数值(NaN)的处理,这会在使用随机输入时自然发生,引用维基百科页面的解释:
如果有多个非数字数值(NaN)输入,其有效负载结果应该来自其中一个非数字数值输入,但标准却没有具体说明。
这意味着,如果要使用浮点运算的话,基本上每个浮点都需要进行“if(is_special(val))val = 0.0”检查配对,这种检查通常可以在硬件中完成,因此也会让用于加密货币挖矿的 ASIC 芯片从中受益。
接下来,哈希率(Hashrate)和“hash-per-watt”又是什么呢?
哈希率是衡量能源成本的指标,只要每个人都以同样的方式进行衡量,每单位的能源消耗就不那么重要——矿工也会继续投入尽可能多的能源挖矿。不过即便你把测量单位从 1 ETHash (较小单位,比如焦耳)切换成 1 ProgPow-hash(较大单位,比如卡路里),运营成本的经济性其实也不会发生变化。全局哈希率(Global Hashrate)会评估每个人对保护网络共享的总经济权重,只要每个人的贡献都被公平地衡量且使用相同的单位,对于普通矿工来说,切换到 ProgPow 算法不会带来什么变化。
当然,有人会说如果以太坊实施了 ProgPow 算法可能会有助于把矿工集中在拥有高端 GPU 的大矿场里,同时也会刺激矿场把 GPU 升级到最新型号。但是ProgPow 算法开发团队 IfDefElse 需要再次重申的是:规模经济永远都会存在,而且也是现实世界里无法避免的事实。
问题四:相比于 GPU,ASIC 芯片生产商可以使用较小的 GDDR6 内存来获得成本优势。在保持内存成本水平的同时,16 个 GDDR6 4GB 的内存条能够实现两倍的带宽优势,是这样吗?
首先,拥有两倍的带宽优势就需要两倍的计算,这其实是一种线性扩容(linear scaling),并不能看做是一种优势。
其次,我们目前应该还没有为 GDDR6 准备好生产 4GB 内存芯片的准备。全球第三大内存芯片厂商 Micron(美国美光)只生产 8GB 芯片,三星则生产 8 GB和 16 GB芯片。对于内存芯片而言,GDDR6 IO 接口区域是非常昂贵的,而且与存储器单元相比,每一代接口都占用了更多的实际存储器管芯,由于端口物理层(PHY)不能像存储器单元那样通过工艺手段缩小。
不可否认,真正推动内存市场的是一些“长周期买家”,比如游戏机、GPU 等,他们也倾向于支持容量更大的内存。事实上,如今的内存供应商没有动力去大批量生产一个 4GB 的内存,毕竟市场对这种内存容量的需求并不大。
问题五:RTX2090 芯片中有许多模块占用了大量芯片模片区面积,而且对 ProgPow 毫无用处,包括 PCIE、NVLINK、L2Cache、3072 分片单元、64 个 ROP、192 个时间测量单元(TMU)等,如何看待这个问题?
RTX2080 不是讨论这个问题的好参照物,由于一些新功能,英伟达(Nvidia)的 RTX 系列芯片中有些模块占据了大部分芯片模片区面积,比如光线追踪核心等。ProgPow 设计则是与英伟达和 AMD 生态系统中的存量芯片产品搭配使用的,因此无法使用英伟达和 AMD 新款芯片产品中的新功能。
如果想有一个更好类比的话,或许 AMD RX 5xx 系列或是英伟达 GTX 1xxx 系列是个不错的参照。正如我们之前所述,GPU 中也有部分功能没有被 ProgPow 利用,比如:浮点逻辑、二级(L2)缓存、以及纹理缓存和 ROP 等。分片单元是向量数学被执行的地方,这绝对是 ProgPow 所要求的。用于加密货币挖掘的 ASIC 芯片还希望添加能够实现“keccak”功能的区域。作为ProgPow 算法的开发团队,我们估计 ProgPow ASIC 芯片的模片区面积会比同等 GPU 小 30%——但是,即便是在最好的情况下,其功耗最多也只会降低 20%。相比之下,虽然 GPU 上有些逻辑模块没有被充分应用而造成部分芯片模片区面积浪费,但功耗却是最小的。
问题六:与大芯片相比,小芯片的收益会更高吗?
怎么说好呢,这听上去像是在普及芯片制造知识,或许我们需要写一篇《芯片制造 101》的培训文档。此外,对于收益计算公式可以参考一篇 2006 年发表的文章《Compare Logic-Array To ASIC-Chip Cost per Good Die》,其中你会发现,早在 13 年之前芯片收益和流程控制就已经有很大创新了。
对于具有单个功能单元的芯片,模片区面积较小的芯片收益会比模片区面积较大的芯片更高。但是对于现代 GPU 来说,情况并非如此。如今的 GPU 几乎可以任意恢复、组合,小型复制单元的缺陷基本上可以忽略。只要每个可压缩功能单元足够小,那么 GPU 芯片收益几乎可以和功能模块更大的芯片一样高(甚至更高)。
为了更好地解释这个概念,我们可以举一个简单的脑洞实验:
1、假设你有一个大芯片“Giant ChipA”,它占据了整个晶片。这个“Giant ChipA”是由 10 万个可拆卸子组件组成,但是其中必须确保 80% 的子组件是无缺陷的,才能保证“Giant ChipA”正常工作,而在嵌入过程中,坏的子组件会被绕过。
2、另外,假设你还有一个小芯片“Tiny ChipB”,它只有一个功能模块(不可嵌入)组成,但是这个小芯片却小到足以在同一个晶片上装配 10 万个子组件。在这种情况下,只要一个子组件坏了,意味着整个“Tiny ChipB”芯片就是坏的。
3、如果每个晶片上平均分布了 2 万个有缺陷的子组件,那么“Giant ChipA”的收益可以为 100%,因为他们可以将 20% 有缺陷的子组件拆掉,而“Tiny ChipB”的收益可能仅为 80%,因为他们无法拆掉有缺陷的子组件。
如果你看看 AMD 的 Polaris 20 系列产品和英伟达的 GP 104 产品,会在模拟镜头下发现这些 GPU 中部署了大量微小的“可拆卸”子模块组成。

问题七:ASIC 矿机电压可以很轻松地降低到 0.4V,只有 GPU 的二分之一……这样低电压的 ASIC 设计已经被比特币挖矿设备 ASIC 矿机制造商所采用,所以现在我们没有理由不相信他们不会把这种策略应用在 ProgPow ASIC 矿机上,能谈谈这个问题吗?
当芯片仅由计算构成,那么低电压设计才能奏效,比如一个专门针对 SHA256d 挖矿算法计算的 ASIC 矿机。集成其他原件——比如 SRAM,这也是 ProgPow 数据缓存所必需的——的难度极大,也不可能在低电压下工作。
问题八:同样的节能效果也能在 LPDDR4x DRAM 上实现,其功耗比 GDDR6 还低,谈谈这个问题吧。
不能仅考虑能耗问题,LPDDR4x 的带宽比 GDDR6 低很多,前者每个引脚带宽是 4.2Gb / s,后者则是 16Gb / s。LPDDR4x 计算芯片上需要四倍的内存芯片和四倍的内存接口才能达到 GDDR6 相同的性能,这样一算,其成本其实是显著增加的。
值得注意的是,高带宽计算芯片的接口通常是有限的,这意味着芯片模块面积必须要足够大,周边几乎不允许任何信号从芯片脱落到印制电路板(PCB)上,LPDDR4x 设计需要大约四倍的芯片周长焊盘数才能达到相同的带宽,也就是说,其成本不仅仅在存储芯片上,计算芯片区域的成本同样也要计算在里面,所以综合算下来其实总成本并不低。更糟糕的是,由于任何芯片都是以速度为导向的,当芯片模块面积更大的时候,意味着浪费的功率也会更多。
所以,不妨让我们再想想为什么如今的 GPU 不能再 LPDDR4x 上运行。首先,LPDDR4x 在带宽成本上的表现并不尽如人意,对于给定的带宽量级(芯片数量的四倍),LPDDR4x的成本要高出四倍以上,继而导致成本显著增加——LPDDR4x 在 9W 功率时 256 GB/s 带宽的成本约为 150 美元,相比之下 GDDR6 在 11W 功率时同样带宽成本还不到 40 美元,因此 LPDDR4x 并没有让矿工省到什么钱(注意,这里说的是带宽成本,而不是内存容量成本)。
问题九:像英伟达这样的 GPU 生产商雇佣了大约 8000 人来开发 GPU,这些 GPU 也非常复杂;而像 LinZhi 这样的 ASIC 生产商只雇佣了十几个人,而且只开发用于 ETHash 挖矿算法的 ASIC 矿机。这些公司的劳动力成本相差 100 被,因此可不可以说 ASIC 芯片在成本和上市时间方面比 GPU 芯片更具优势。
在此要说的是,规模经济是一个重要因素。GPU 行业也是在全球各种销售渠道中摊销,目前总市场规模大约为 4200 亿美元,其中 AMD 市值约为 116 亿美元,英伟达约为 1545 亿美元,最大的英特尔约为 2548 亿美元。仅就内存市场而言,还需要在这个总规模达到 5000 亿美元的行业里分摊物理端口(PHY)和晶片的成本,其中拥有 320,671 名员工的三星电子市值约为 3259 亿美元,他们也是在美国最活跃的专利申请者;第二名是拥有 34,100 名员工的Micron Technology,其市值约为 601 亿美元,但是第一个开发出 20Gbps 高速 GDDR6 内存的芯片制造商;海力士拥有 187,903 名员工,市值约为 568 亿美元,他们开发了全球首款1Ynm 16Gb DDR5 DRAM。相比之下,用于加密货币挖矿的 ASIC 芯片行业总市值不过 1460 亿美元,其中 730 亿属于比特币。
另外我们还要看看上市时间和技术接受模型(TAM),在此不妨以著名的 S9 矿机继任者开发时间作为参考。如果经过充分研发、并且计算难度不是很高的 SHA256d 算法计算芯片都需要耗费三年时间才能进行迭代,那么又有什么可以保证像 GPU 一样的、支持 ProgPow 算法的 ASIC 矿机快速投产上市呢?我们还可以分析一下最近挖掘以太坊加密货币的 ASIC 矿机情况,GDDR6 芯片样品试用期已经有一年时间了,到目前仍然没有发布能够被广泛应用的新版本产品。
ProgPow 核心开发团队 IfDefElse 的最后一点想法
ProgPow 其实针对是一种挖矿硬件,这种硬件受到了规模经济的支持,具有高可见性并获得了较大竞争优势。
ProgPow 核心开发团队 IfDefElse 规模并不大,而且团队成员也都有全职工作,所以他们无法及时回复所有问题和文章,更没时间在各种加密货币和区块链线上论坛里喋喋不休。虽然 IfDefElse 对硬件设计和开发非常感兴趣,但他们仍然建议涉足这一领域的人需要保持谨慎,因为硬件和软件一样,是一个多元化的领域,即便你是一个对加密货币挖矿 ASIC 芯片非常熟悉的大咖,但在 GPU-ASIC 领域里可能无法成为一个专家。
本文来自 Medium,原文作者为 ProgPow 算法核心开发团队 IfDefElse
译者:Odaily 星球日报译者 | Moni
来源:星球日报
声明:本内容为作者独立观点,不代表 CoinVoice 立场,且不构成投资建议,请谨慎对待,如需报道或加入交流群,请联系微信:VOICE-V。

简介:探索真实区块链










评论0条